Well here we are! Sean and I have traveled via our favorite domestic airline – Southwest – from Dallas to Seattle, for our annual vacation / work week / SQL reunion: PASS Summit!

I’m going to try writing a bit about each day I’m here, just because it might be useful. Or, in a year or two, nostalgic. Or just to have something like letters from camp;
“Hi there, internet friends, today at camp it rained some more, and I talked to 30 new friends, and I got a squishy stress ball from the vendor in the next booth…”
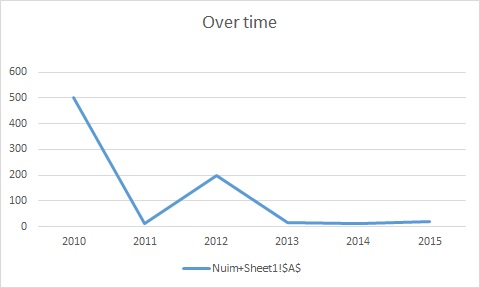
One Decade of Dallas to Seattle
This will be my tenth year at PASS Summit! Ten years ago, I won a little contest that got little, lower-midlevel Jen to the Summit, and introduced me to a whole heckofa lot of SQL people online. That was fun
Since then I’ve had a lot of different experiences with Summit. We spent several years interviewing really cool, intelligent, and/or famous ( 🙂 ) SQL people. We have spoken at Summit a few times, been on panels, spoken to vendors and reps, played games, and even did a precon one year. We’ve hosted parties and meetups, raised money for charity, ran short runs and long runs, and we (okay, I) have sun an AWFUL lot of karaoke, fueled by pots of green tea and/or beer.

It’s a good time.
“But I’m not at Summit,” you say.
And I always feel for the folks who don’t get to make it. After all, it’s a week out of your life, AND it’s a big expense that your company won’t always spring for, and so on.
So, while I will be writing at least one blog a day about our experiences here in Seattle this week, I will also do my best to bring you, you fine people at home, various goodies and resources and freebies, straight to your computer monitors, from yours truly. you deserve it.
What’s coming up?
We always try to come to Seattle early so that we can enjoy the city, and meet up with a friend or two, before the real rush starts. Tonight we’re all settled into a lovely apartment near the waterfront, and we’ll go get some supplies for dinner / breakfast / tea / coffee.
Tomorrow – Sunday – who knows? Maybe a rainy bike ride around the city, most likely some time with friends. And I absolutely HAVE to finish up the last bits of the SQL Yearbook, a project I’ve assigned myself after years of hoping someone else would come up with the idea independently. 🙂 No such luck. It’s been a fun project, though.
Monday is when things start up for real. Sean and I are teaching a session each at the Seattle Freecon, which I’m looking forward to! And in the evening, we ourselves are hosting our annual Donut Meetup, sponsored by MinionWare (also us).
We can talk about Tuesday onward another day, but you’ll get a general idea if you glance over my “All about PASS Summit 2018” post.
Okay, TTFN. Time to go pick up supplies!
Happy days,
Jen